Takeaways from PyData Amsterdam 2019
Posted on Thu 14 March 2019 in Generic
Written by Enrico Rotundo & Michael Chong.
PyData Amsterdam 2019 it’s a wrap. It has been an amazing two days conference (plus one of workshops) where experts and users of data analytics tools shared their research, approaches and mistakes in a friendly and inclusive environment.
In this post, we present some takeaways from the conference, and a few reasons why you should consider going the next time.

Our favourite talks
Generally speaking, the level of the talks was very good, with a mix of experienced presenters and novices, professional entertainers and hardcore technical experts. Amongst several very good talks, these were our favourites:
The Profession of Solving (the Wrong Problem), by Vincent D. Warmerdam (GoDataDriven) Vincent is an entertaining speaker, his talk was fun, spot on in describing mistakes we all make, and very helpful in putting some things in perspective. Through a few examples he illustrated how we can get stuck because we look at the wrong thing or we approach it the wrong way, and often enough we are so much focused on the details of the technology we are using that we forget about the problem itself. By changing perspective you can often get to a solution that seemed impossible before.
People dreamt about the solution. Not the problem.
There are a few practical ways to help you changing perspective when stuck, and some good practices you should adopt always. These include focusing on the problem, rather than on the solution or on the algorithm; talking with your client again and again, understand his pain points and needs; set up a pipeline such that you can evaluate the impact of anything, before implementing the solution. Oh, and don’t forget to “go to your local theatre, there are some AMAZING things happening on stage”
Online machine learning with creme by Max Halford (Université Paul Sabatier, Toulouse) Max had this entertaining presentation full of memes and pop references, on a topic we don’t discuss often: doing machine learning on data streams. We are so used to think of machine learning as a batch problem — that we often forget that real data often is generated sequentially. He presented Creme (from inCREMEntal learning), a python library to do online machine learning, a regime where the model learns one observation at a time. This enables rapid-deployment, right after the 1st data point comes in 🤠, as well as a low-memory footprint (doesn’t need to load the whole dataset into memory).
The library is quite young, however the core team seems very enthusiastic and committed. They need feedback on real-life use cases (i.e. real streaming data), to drive the development of the library (yes, things go wrong in real scenarios). If you are a bit confused about the usefulness of the approach, don’t worry. We are as well. What is clear is that we are very much used to the batch approach that seldom we question it. To better understand all the implications of doing online learning, we will for sure try Creme as soon as we have a chance to do so.
Sebenz.ai — South African job creation through gamified data labeling for machine learning by Alex Conway (Sebenz.ai) Alex’s talk was the most colourful of the two days both literally and in a figurative way. He presented Sebenz.ai, a way to label your data by making people play a sort of game on their smartphones (and get paid). If this sounds similar to a Mechanical Turk, it is because it kind of is. But AWS’s tool is quite old, and there is nothing bad in getting out of a sort of monopoly.
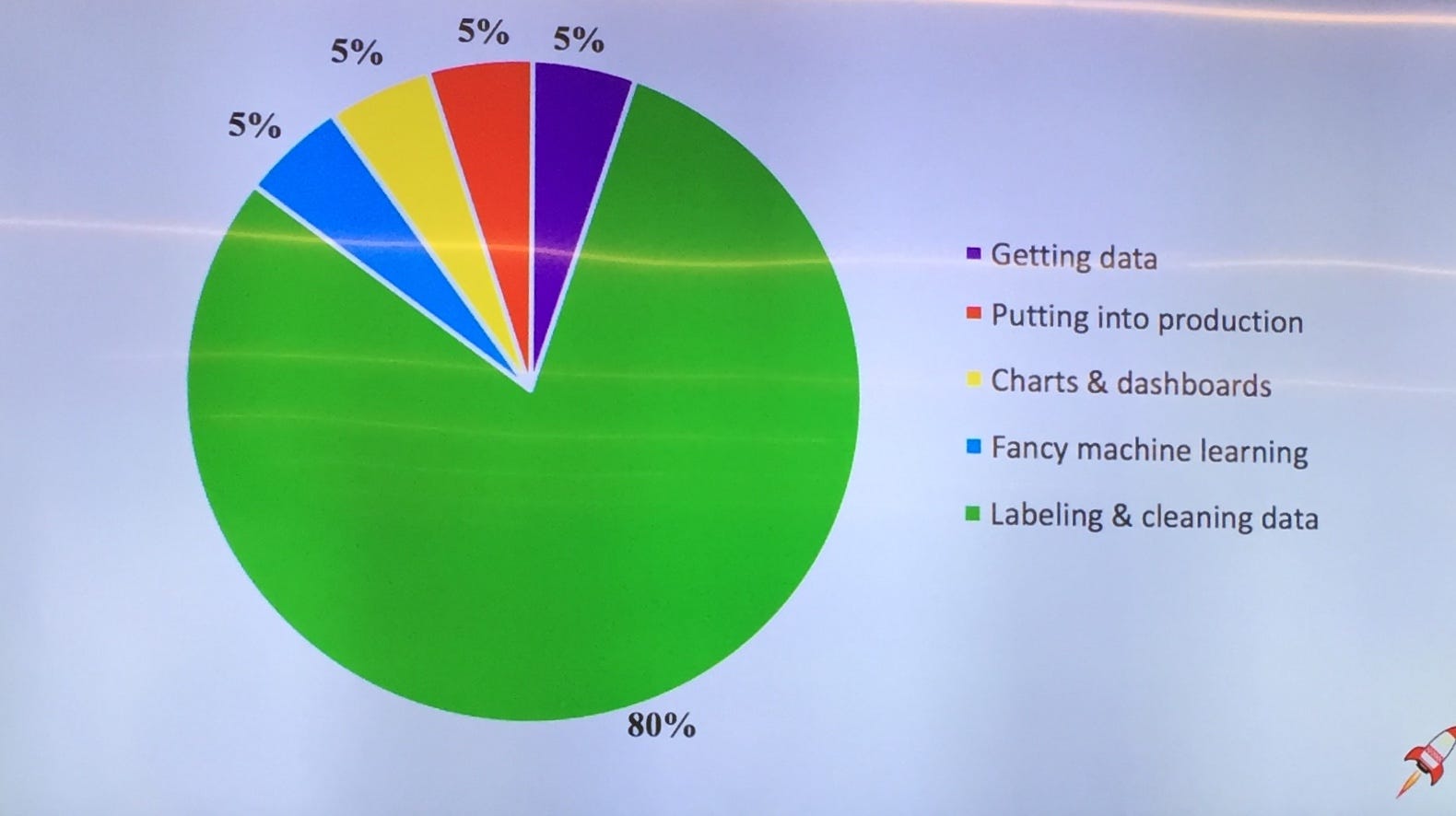
Generally we are very much concerned with the amount of data, and we might overlook the quality of data, which is scarce and precious. And properly labelled data is even rarer. Ask for a price quotation to buy annotated images if you don’t believe it. As Alex loves to put it:
if you are paying a data scientist with a PhD to label your data you are not making a good deal
Not all the data is like oil. Having an alternative tool to label your images, or to transcribe your audio notes, by a company that promise to ensure at least minimum wage retribution and that tries to give jobs in a country with high levels of unemployment, can’t do any harm.
Ethics and inclusion awareness is rising
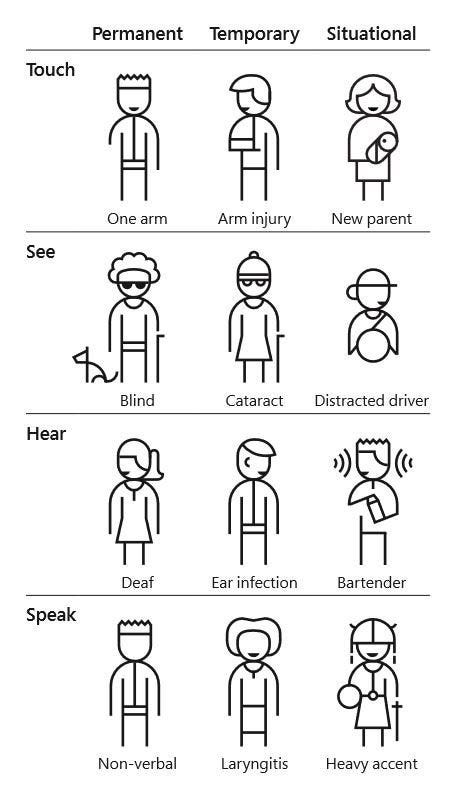
The fact that inclusion, diversity and ethics have become a central topic is clear from the fact that the first keynote, an excellent presentation by Sasha Romijn, was about the need of empathy in our communities and products. Sasha highlighted unintentional non-inclusive behaviours we may have, and the fact that until we experience being discriminated against, it is very difficult to realise the complexity of it! A thing that blew our mind was the realisation that when we make our product accessible to people with disabilities we may accidentally make it available for a set of people that we did not think about, as illustrated here
Speaking of discrimination, we were happy to see that PyData adopted a code of conduct and made sure to share it with all the participants both online and in the goodies bag.
Interestingly enough, several times during the conference questions were asked about the ethical consequences of a solution or of a project, stimulating debate and awareness.
Finally, in at least a couple of talks the topic of filter bubbles was touched and the talk by Sanne Vrijenhoek was focused on how to measure diversity in news recommendations.
You’ll meet cool people
Such as core developers of open-source packages you use every day, such as Ralf Gommers (SciPy, NumPy) and Carlos Córdoba (Spyder)
Conclusions
Attending this conference was a remarkable experience. Whether you’re a techie or a business savvy you’ll get valid takeaways from the community. And it’s not all! Don’t forget to follow PyData Amsterdam’s meetup page to stay posted on the monthly meetups.
Acknowledgments: we want to thank for giving us the possibility to attend this event. Also, we’d like to thank all the people who worked to make PyData Amsterdam 2019 such a successful events, the Organizing Committee, the volunteers, the speakers andNumFOCUS.
Originally published at https://medium.com on May 14, 2019.